Platform Architecture
SDL is a layered, modular platform designed for tactical and enterprise data operations. This page provides a high-level architectural overview with pointers to detailed documentation for each capability area.
Architecture Overview
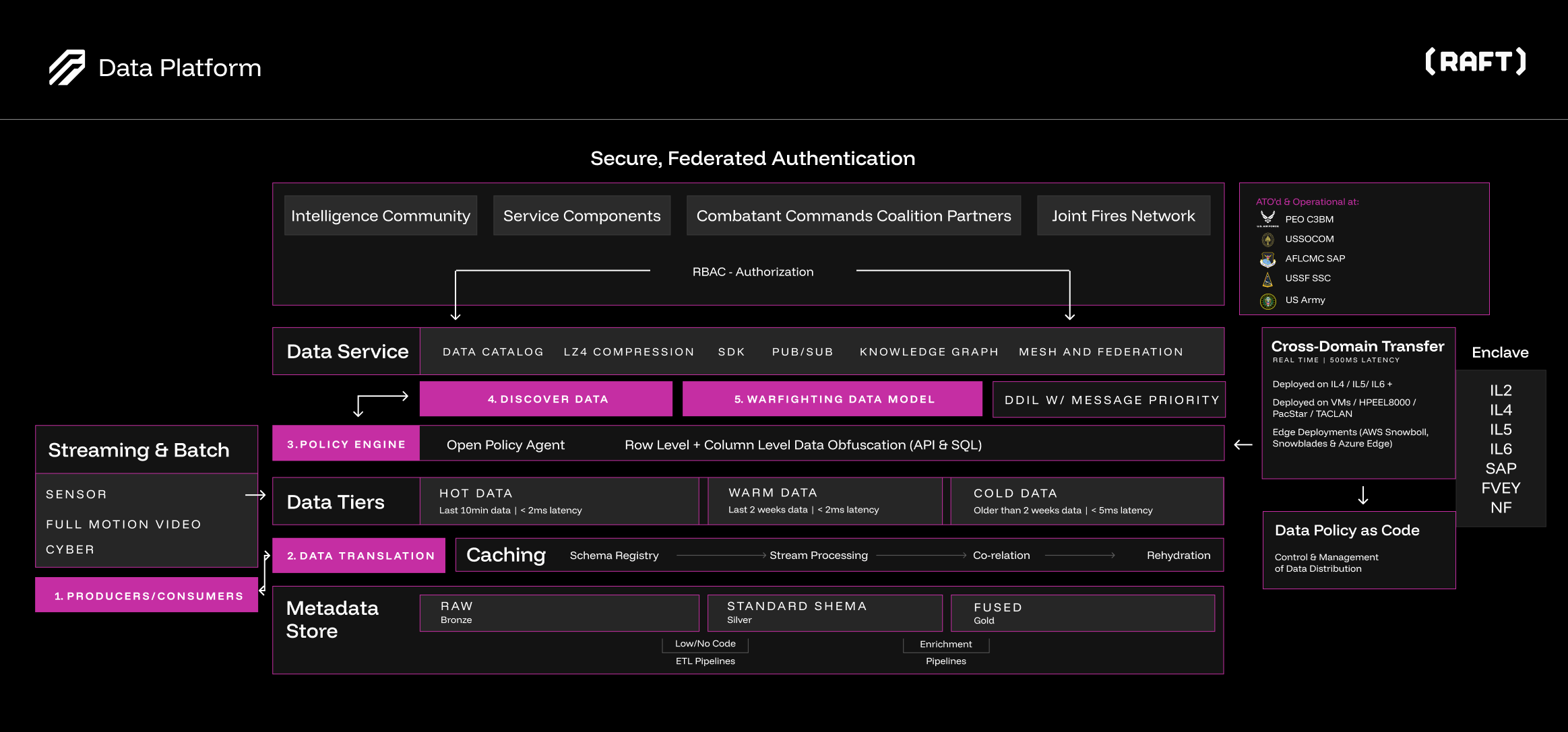
The platform is organized into horizontal layers, each responsible for a distinct set of capabilities. Layers communicate through well-defined interfaces, enabling independent deployment, scaling, and evolution.
Architecture Layers
Ingestion Layer
The ingestion layer connects SDL to external data sources. It supports connectors for event streaming, gRPC, TAK servers, TCP, PostGIS, and other protocols.
The layer is format-agnostic: 14+ tactical data formats (including CoT, AIS, ADS-B, Link-16, GCCS-J, SIGINT, and others) are converted to the canonical data model through configurable transformers. This decouples the platform from source-specific formats, enabling new sources to be added without modifying downstream components.
Processing Layer
The processing layer handles data transformation, enrichment, and schema validation. It provides the following integration patterns:
- Native Transformation Path
-
Data flows through transformers without being forced into the data model. This supports coalition interoperability, legacy system integration, exploratory data ingestion, and high-fidelity passthrough where downstream systems require the source format.
Both paths are processed through the transformation hub, which manages pipeline orchestration, error handling, and monitoring.
Query and Analytics Layer
The query and analytics layer provides multiple access patterns for consuming data:
-
Federated SQL — A distributed SQL engine that queries across heterogeneous data sources (relational databases, object storage, event streams) through a single SQL interface.
-
Virtual Knowledge Graph (VKG) — Ontology-Based Data Access (OBDA) maps data to BFO/CCO ontology terms, enabling SPARQL queries across data from both the Data Model Path and Native Transformation Path.
-
Real-time analytics — Low-latency analytics on streaming data for operational dashboards and alerts.
-
Data visualization — Interactive dashboards for operational monitoring, data exploration, and reporting.
Storage Layer
The storage layer implements a tiered architecture for cost-effective, performance-optimized data retention:
-
Hot tier — Low-latency access for active operational data. Recent entities, tasks, and streaming updates.
-
Warm tier — Balanced latency and cost for recent historical data. Queryable through federated SQL.
-
Cold tier — Object storage (S3-compatible) for long-term retention and archival.
The metadata lake follows a Bronze-Silver-Gold pattern:
-
Bronze — Raw ingested data in source format.
-
Silver — Cleaned, validated, and schema-conformant data.
-
Gold — Enriched, correlated, and analytics-ready data products.
Security and Governance Layer
Security and governance are enforced across all other layers:
-
Policy engine — Attribute-based access control (ABAC) with fine-grained policy evaluation.
-
Classification markings — ISM-format security markings on every entity and task.
-
Obfuscation — Row-level and column-level data obfuscation based on the requester’s clearance and need-to-know.
-
Audit logging — Complete data lineage and access tracking for compliance and after-action review.
API Layer
The API layer provides unified access to all platform capabilities:
-
REST API — JSON over HTTP for web integrations, scripting, and ad-hoc queries.
-
gRPC API — High-performance protobuf-based access with bidirectional streaming.
-
SDKs — Client libraries in Go, Java, and Python with built-in connection management, retry logic, and TLS configuration.
Capability-to-Documentation Mapping
Use the following table to navigate from a capability area to its detailed documentation:
| Capability | Documentation |
|---|---|
Event Streaming |
|
Object Storage |
|
Federated SQL |
|
Operational Monitoring |
|
Data Science Notebooks |
|
Identity and Access Management |
|
Data Catalog |
|
Data Pipelines |
|
GeoServer |
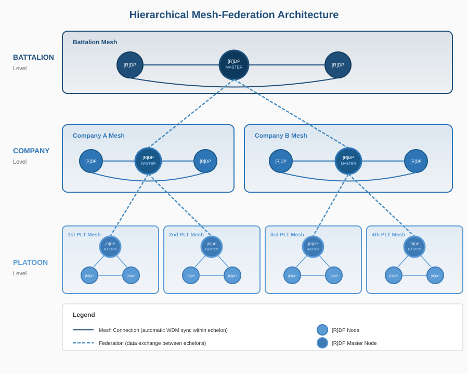
Hierarchical Mesh-Federation Architecture
SDL deployments typically follow a hierarchical architecture that mirrors military echelon structures.
Echelon Hierarchy
The architecture supports multi-echelon deployments where each level operates as an autonomous SDL instance:
- Platoon
-
Edge-deployed nodes with constrained compute and bandwidth. Nodes within a platoon sync bidirectionally to maintain a shared operational picture. Platoon nodes push upward to the Company echelon through unidirectional edges.
- Company
-
Aggregates data from multiple platoon nodes. Company-level nodes maintain the combined picture from all subordinate platoons. Company nodes push upward to Battalion through unidirectional edges.
- Battalion and Above
-
Enterprise-level aggregation with full compute and bandwidth capacity. Receives data from all subordinate echelons and provides the widest operational picture. May also push data downward (e.g., tasking, intelligence products) through directed edges.
Mesh Within, Federation Between
Each echelon level runs its own internal mesh:
-
Within an echelon: Nodes sync bidirectionally, forming a fully connected mesh. Any node’s update propagates to all other nodes at the same echelon level.
-
Between echelons: Directed (typically unidirectional) edges connect echelons. Data flows upward for aggregation and selectively downward for tasking and dissemination.
This architecture provides resilience at each level — if the inter-echelon link goes down, nodes within an echelon continue to operate and sync with each other. When the link recovers, delta sync brings the higher echelon back up to date.
Bidirectional vs. Unidirectional Edges
| Edge Type | Usage |
|---|---|
Bidirectional |
Within an echelon, between peers at the same classification level. Full convergence — both nodes have the same data. |
Unidirectional (push up) |
From lower echelon to higher echelon. Data flows from edge to enterprise for aggregation. |
Unidirectional (push down) |
From higher echelon to lower echelon. Tasking, intelligence products, and reference data flow from enterprise to edge. |
Cross-domain |
Between classification levels. Data flows through cross-domain guards with XSD validation. Typically unidirectional from lower to higher classification. |
Related Topics
-
Data Pipelines — Transformation and ingestion pipeline details
-
Security — Policy engine, ABAC, and classification markings