Data Tiering & Storage
SDL implements a multi-tier storage architecture optimized for different access patterns and data freshness requirements. Data moves through well-defined tiers — from raw ingestion through normalization and fusion — with each tier providing the appropriate balance of latency, throughput, and storage efficiency.
Storage Tiers
The platform organizes operational data into three access tiers based on age and query frequency:
| Tier | Latency | Description | Capacity Profile |
|---|---|---|---|
Hot |
<2ms |
Last 10 minutes of operational data. Optimized for real-time queries and the highest throughput requirements. |
Highest throughput |
Warm |
<2 sec |
Last 2 weeks of data. Balances query speed with increased storage capacity for recent historical access. |
Balanced speed and capacity |
Cold |
<5 sec |
Older data beyond the warm window. Optimized for storage efficiency while maintaining query latency under 5 seconds. |
Optimized for storage efficiency |
Tier boundaries are configurable per deployment. Data transitions between tiers automatically based on age, with no manual intervention required.
Metadata Store
Beyond the operational access tiers, the platform maintains a structured metadata pipeline that tracks data quality and provenance:
- Bronze (RAW)
-
Ingested data in its original format. This tier serves as the immutable audit copy, preserving the exact representation received from the source system. No transformations are applied at this stage.
- Silver (Standard Schema)
-
Data normalized to the canonical data model. Records are validated against the schema, enriched with standard metadata (timestamps, source identifiers, classification markings), and made available for downstream processing.
- Gold (Fused)
-
Conflict-resolved, multi-source fused entities with full provenance chains. When multiple sources report on the same real-world entity, the fusion process reconciles conflicts, merges attributes, and produces a single authoritative record that retains links to every contributing source.
Object Storage
SDL provides S3-compatible object storage for bulk data, attachments, and artifacts that fall outside the structured entity model:
-
S3-compatible APIs for programmatic access using standard tooling and client libraries.
-
LZ4 compression applied to stored objects for storage efficiency without significant CPU overhead.
-
Lifecycle policies for automatic tier migration, moving infrequently accessed objects to lower-cost storage classes on a configurable schedule.
-
Multi-region replication where the deployment topology and network connectivity support it, ensuring object availability across geographically distributed nodes.
ETL & Enrichment Pipelines
Data movement through the tier hierarchy is managed by configurable pipelines. Operators build, monitor, and manage pipelines through the pipeline catalog, which provides a centralized view of all active, inactive, and degraded pipelines across the deployment.
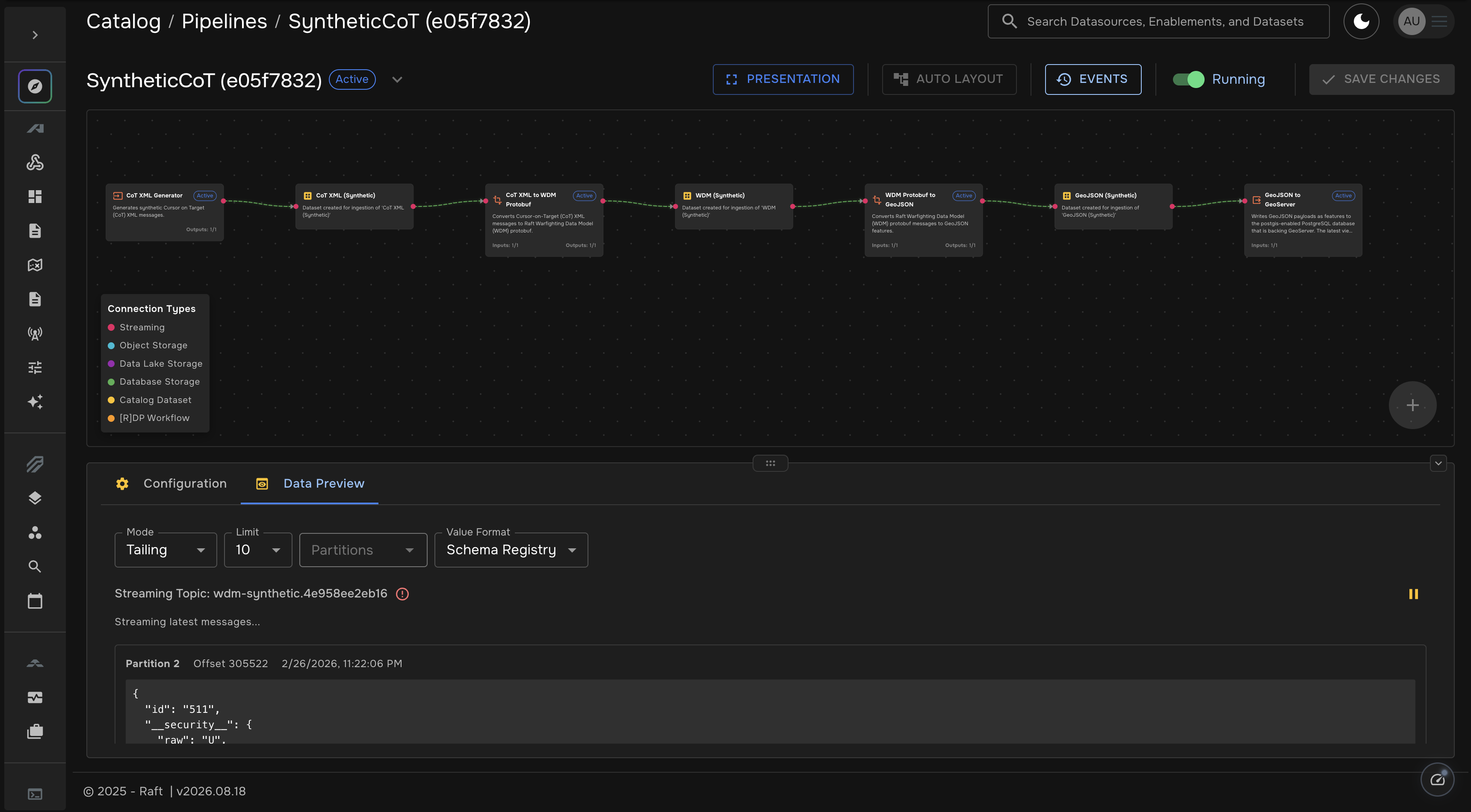
Each pipeline is assembled visually as a directed graph of stages. Operators chain together data generators, format transformers, storage connectors, and enrichment steps using a drag-and-drop builder. The built-in data preview shows live streaming records flowing through the pipeline, enabling operators to verify transformations in real time before promoting a pipeline to production.
- Low/No-Code ETL configuration
-
Pipeline definitions use declarative configuration that allows operators to define extraction, transformation, and loading workflows without writing custom code.
- Enrichment pipelines
-
Dedicated enrichment stages add context to records as they progress through the tiers. Enrichments include geospatial correlation, temporal alignment, and classification marking assignment based on source and content analysis.
- Schema validation at tier boundaries
-
Each transition between tiers — Bronze to Silver, Silver to Gold — includes schema validation to ensure data integrity. Records that fail validation are flagged and routed to exception handling rather than silently propagated.
- Lineage tracking
-
The platform maintains a complete lineage record from raw ingestion through fusion. Every transformation, enrichment, and merge operation is logged, enabling operators to trace any fused entity back to its original source records.